



このサイトでは大学共同利用機関法人人間文化研究機構国立国語研究所と文部科学省科学研究費特定領域研究「日本語コーパス」プロジェクトが共同で開発した 『現代日本語書き言葉均衡コーパス』(BCCWJ: Balanced Corpus of Contemporary Written Japanese)のデータを検索できます。 BCCWJ には、現代の日本語の書き言葉の全体像を把握できるように集められたサンプルが約1億語収録されています。 2024 年度に文化庁からの委託事業として始まった BCCWJ の拡張プロジェクト(BCCWJ2)で構築したデータも順次追加していきます。
本サイトで可能な検索は文字列検索(全文検索)だけですが、形態論情報を利用した検索サイト「中納言」も開設しています。 詳しくは以下をご覧下さい。なお、中納言の利用には申請が必要です。

コーパスの構築にあたっては、全サンプルについて著作権処理を実施しており、その結果、権利者の方から利用を拒否されたサンプルは公開対象から除外してあります。 BCCWJ2 のサンプルについては著作権法の「デジタル化・ネットワーク化の進展に対応した柔軟な権利制限規定」(第 30 条の 4、第 47 条の 4、第 47 条の 5) に基づいた「軽微な利用」の範囲内で適法に公開しています。
利用法
- まず、現在表示されている画面下の「利用条件を読んで少納言を使う」ボタンをクリックして、利用条件に同意したうえで、検索条件指定画面に移動します。
- 次に検索したい文字列を「検索文字列」に全角文字で入力してください。 本コーパスではアルファベット、数字、句読点もふくめてすべての文字が全角で入力されていますので、半角文字は使わないでください。
- 検索文字列指定画面ではテキストの「メディア/ジャンル」と「期間」を指定することができます。 より細かいジャンルや年を指定する場合は をクリックして選択肢を開いたのち、指定したい条件をチェックしてください。
- 検索文字列を入力したら「検索」ボタンをクリックしてください。検索結果画面に検索結果が表示されます。
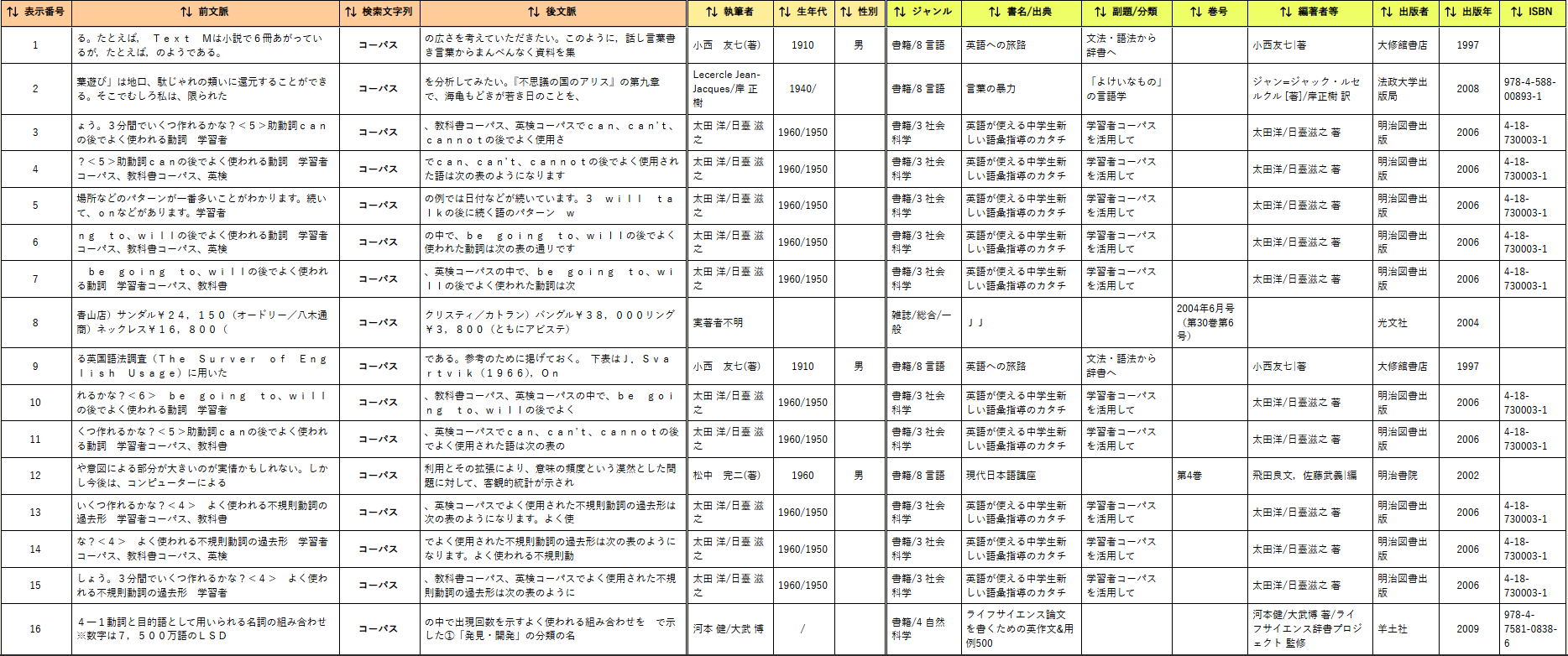
- 検索結果は検索結果画面に表示されます。 左から順に「表示番号」「前文脈」「検索文字列」「後文脈」「執筆者」「生年代」「性別」「ジャンル」「書名/出典」「副題/分類」「巻号」「編著者等」「出版者」「出版年」「ISBN」が表示されます。
- 検索結果画面では表の見出しをクリックして Asc, Desc を選択するとその列の文字列で昇順、降順にソートすることができます。 ソートを解除して検索結果の初期状態にもどすには、表の見出しをクリックして Asc, Desc のチェックを外してください。
本サイトの検索対象となっているサンプル
2026 年 3 月現在、検索対象となっているのは、以下の 11 種のデータ、合計約 1 億 2800 万語です。サンプルは、それぞれ無作為抽出によって抜き出しています。
- 書籍(1971〜2005 年、22,058 件、約 6,270 万語),(BCCWJ2 : 2006〜2010 年、5,943 件、約 2,300 万語)
- 雑誌(2001〜2005 年、1,996 件、約 440 万語)
- 新聞(2001〜2005 年、1,473 件、約 140 万語)
- 白書(1976〜2005 年、1,500 件、約 490 万語)
- 教科書(2005〜2007 年、412 件、約 90 万語)
- 広報紙(2008 年、354 件、約 380 万語)
- Yahoo! 知恵袋(2005 年、91,445 件、約 1,030 万語)
- Yahoo! ブログ(2008 年、52,680 件、約 1,020 万語)
- 韻文(1980〜2005 年、252 件、約 20 万語)
- 法律(1976〜2005 年、346 件、約 110 万語)
- 国会会議録(1976〜2005 年、159 件、約 510 万語)
()内は、それぞれのデータの発行年、サンプル数、句読点・記号を除いた推定語数です。
サンプルの長さ
ひとつのテキストからは長さの異なる二種類のサンプルを採取しています。 ひとつは長さを 1000 字に固定したサンプル(固定長サンプル)、もうひとつは、節や章など文章の意味上のまとまりに対応した単位の全体です(可変長サンプル)。 これまでの調査によれば、可変長サンプルの平均長は新聞で約 1000 字、書籍で 4000 字弱です。
サンプルの選択基準
本コーパスに収録するサンプルの大部分は、公開されている各種出版データや東京都下の公共図書館の蔵書データを母集団として、そこから無作為に抽出されたものです。 特定の本や雑誌の特定の一部分がサンプルとして選択されているのは、無作為抽出の結果、偶然そこが選択された結果です。 語学ないし文学の立場からの価値判断は一切おこなっていません。 本コーパスが現代日本語の書き言葉を代表するとみなされうるのは、新聞社などが実施する無作為抽出にもとづく世論調査が日本国民を代表するのと同じ意味においてです。
それでは、実際に検索条件を指定して、少納言をご利用ください。
検索にあたっての注意点
- 検索文字列の制約:
- 本サイトで検索できる文字列は最長で 10 文字までです。
- 検索方式:
- 本サイトでは全文検索をおこなっていますので、指定された文字列を含むすべてのテキストが検索されます。 例えば検索文字列に「リズム」を指定すると、「リズム」だけでなく、「アルゴリズム」や「フォルマリズム」などが検索され、「国語」を検索すると「母国語」「外国語」なども検索されます (本コーパスの正式公開版では、単語を単位とした検索ができるようになります)。
- 検索結果の上限:
- 検索文字列によっては非常に多くの検索結果が得られることがあります。 その場合、本サイトでは 500 件で表示をうちきります。 ただし最初に見つかった 500 件を表示するのではなく、一旦コーパス全体を検索したうえで、無作為に 500 件を選んで表示します。 これは最初に見つかった 500 件だけを表示すると、検索結果がコーパスの冒頭部分に偏ってしまうためです。
- 検索結果とセッションの関係:
- 1 回のセッション(本サイトへの接続)中に同じ文字列を検索した場合には同じ検索結果が返ってきます。 しかし一旦セッションを打ち切り、その後再度接続した場合には、セッションごとに異なる検索結果が表示されます。
- 結果のダウンロード:
- 本サイトでは検索結果をダウンロードすることはできません。
さらに詳しい情報
以下の URL に本コーパスに関連する情報が公開されています。ご参照ください。
お問い合せ
本サイトについてのお問い合わせは以下のフォームからお願いします。